Published on May 22, 2021
Machine Learning-Optimized Synthesis of Doped TiO2 with Improved Photocatalytic Performance: A Multi-Step Workflow Supported by Designed Wet-Lab Experiments
Journal of Alloys and Compounds
Keywords: machine learning , photocatalysis
Abstract
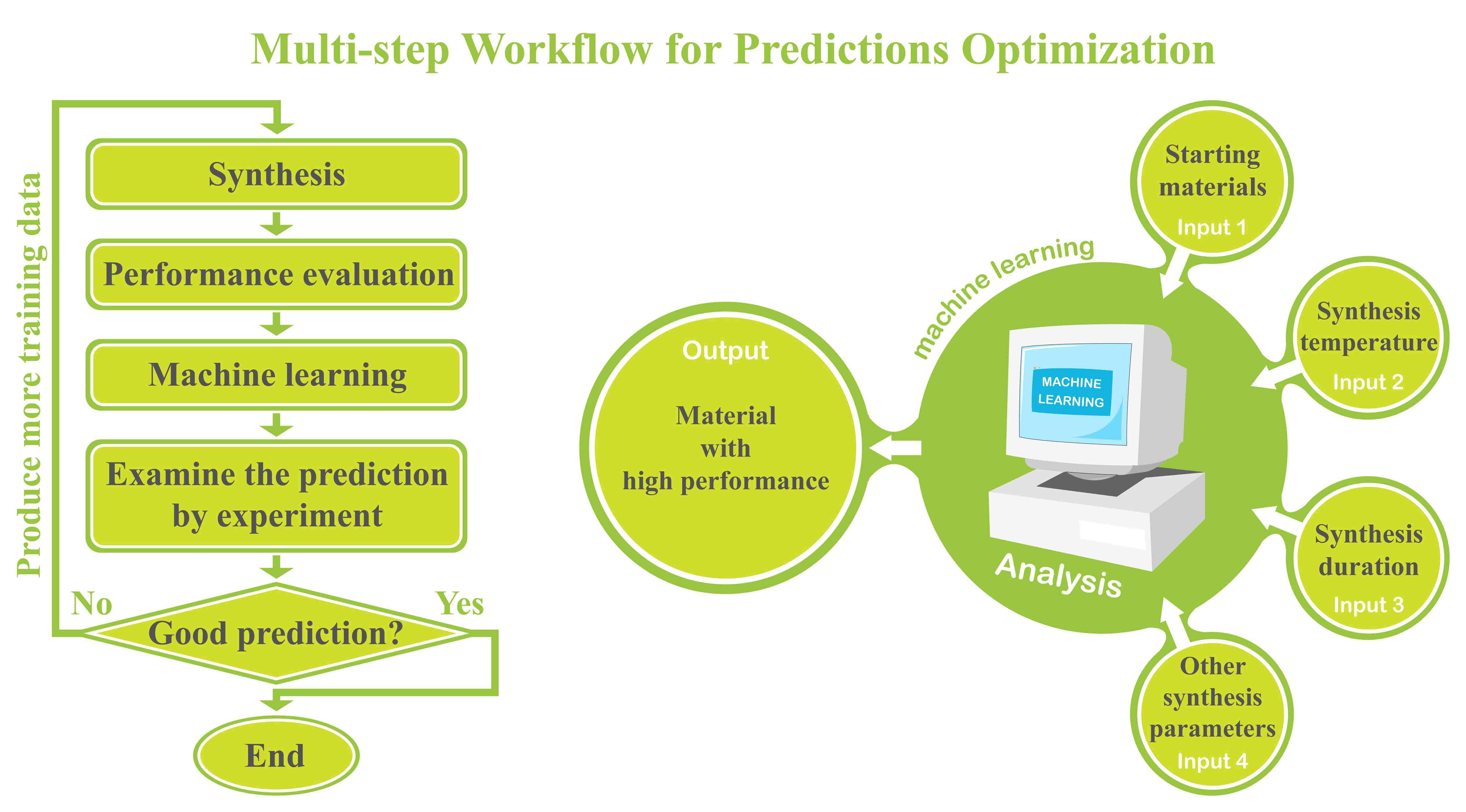
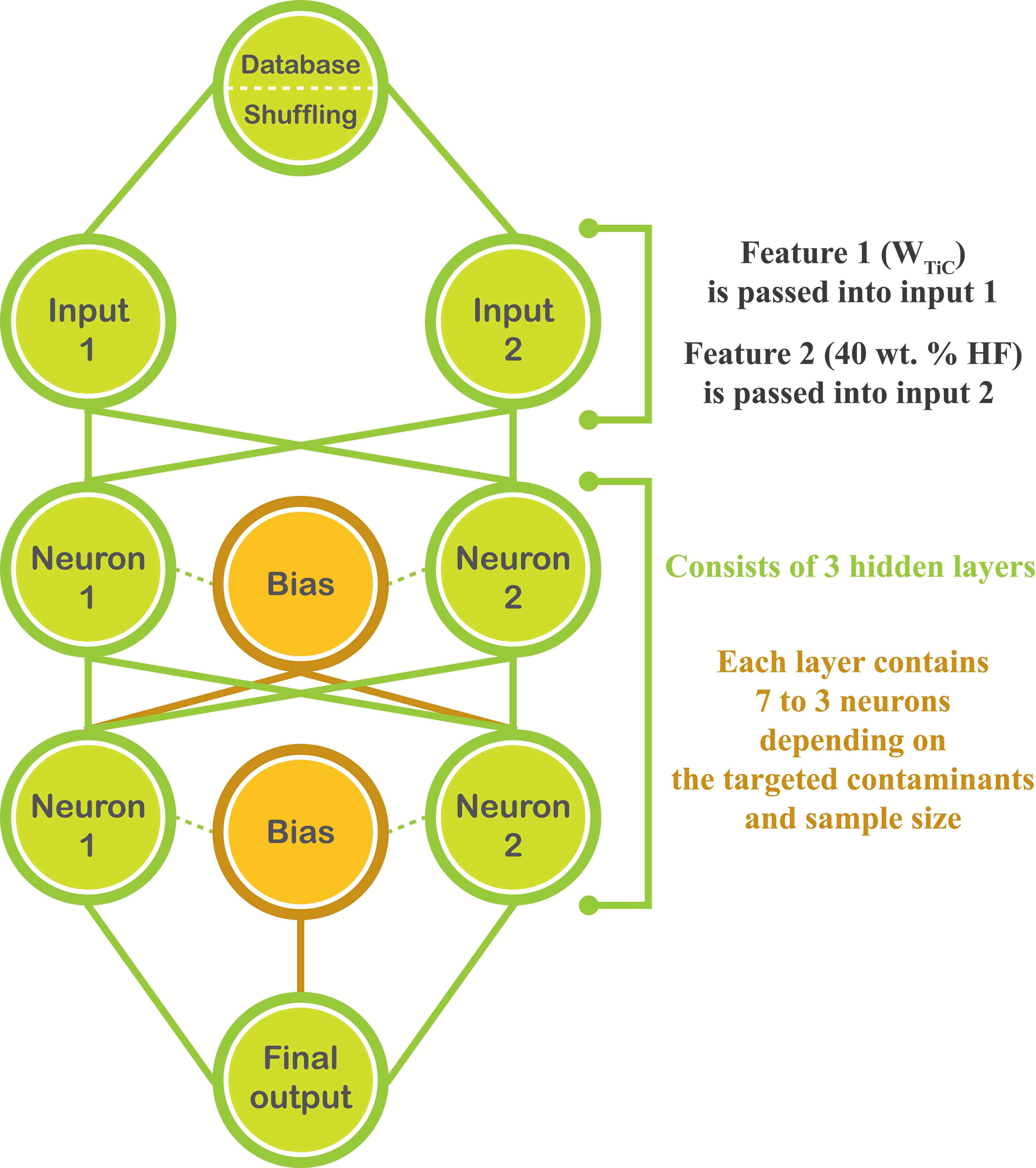
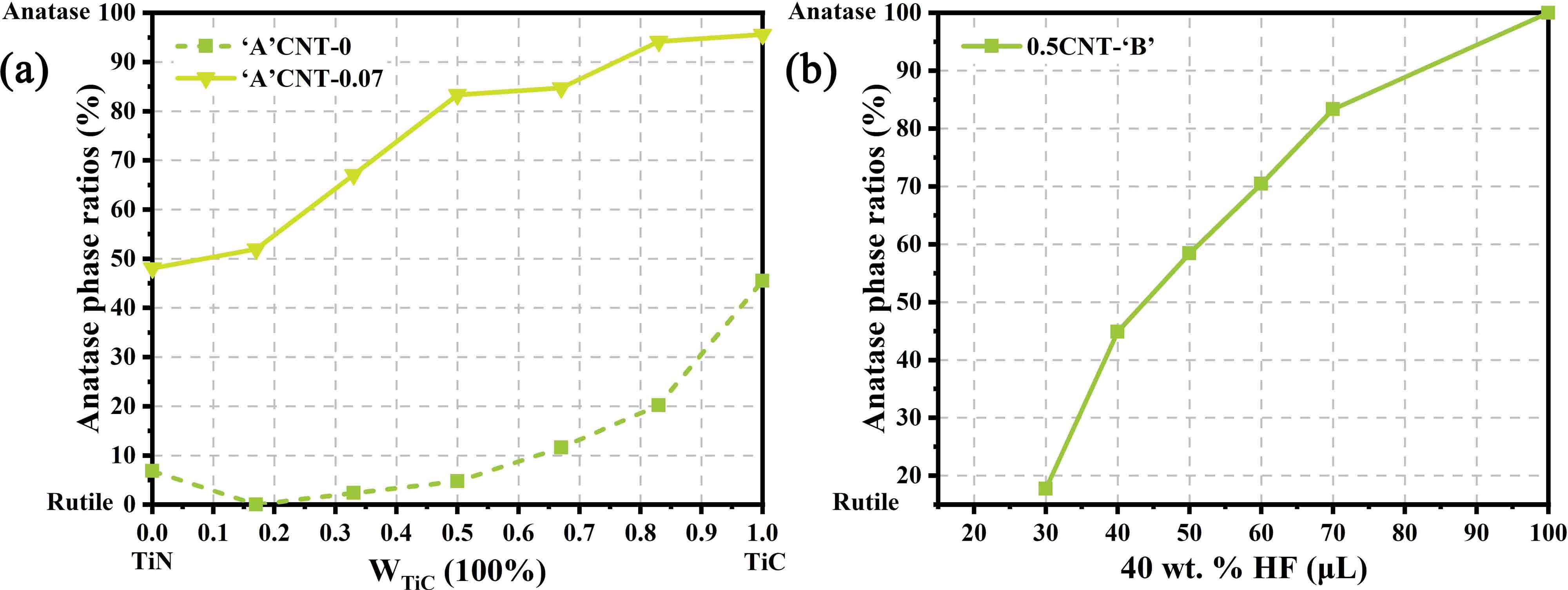
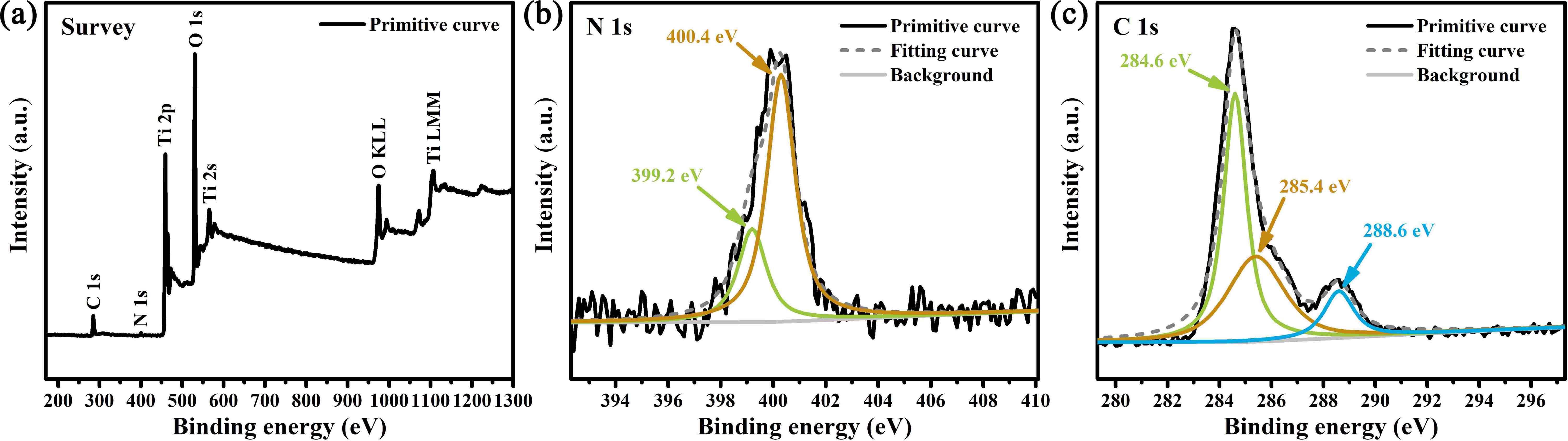
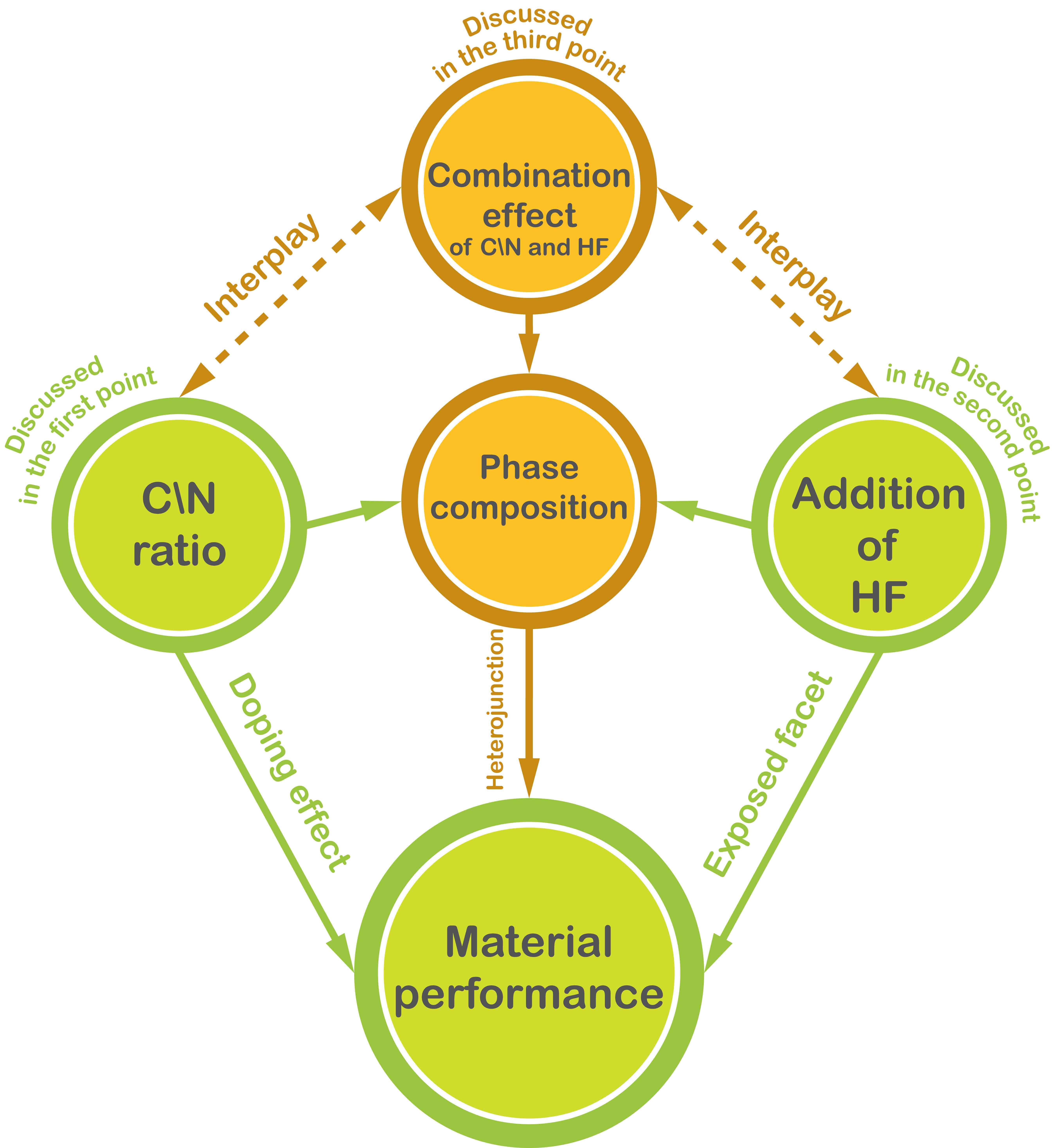
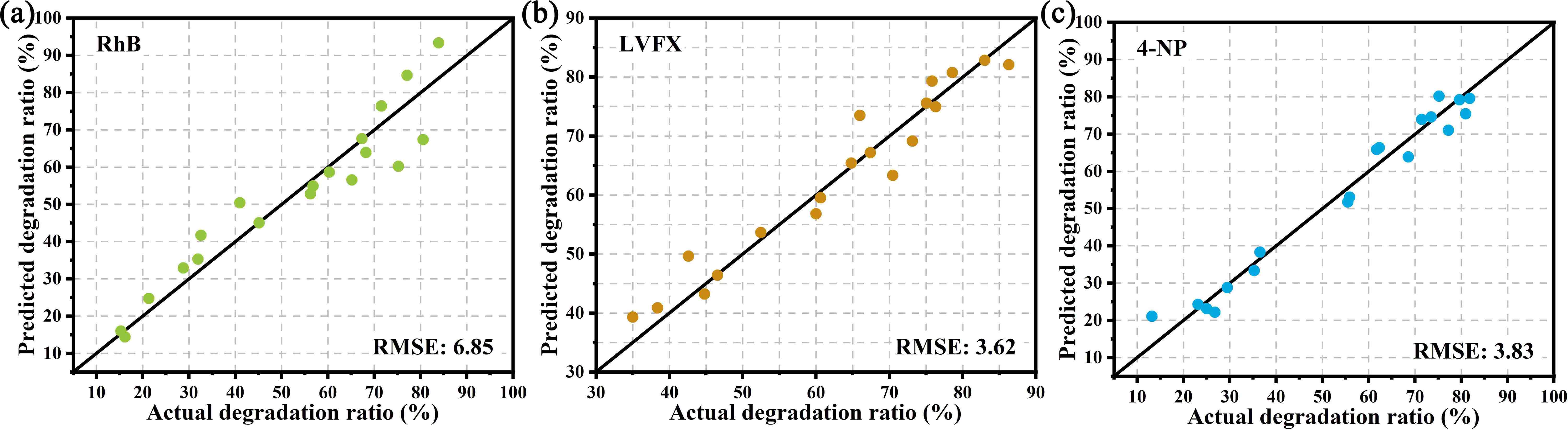
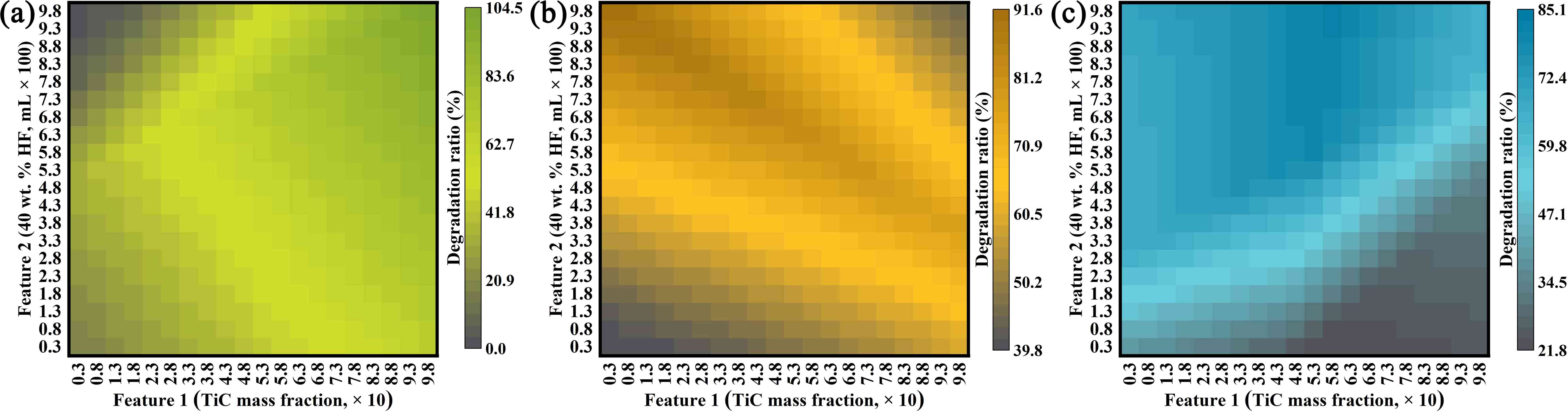
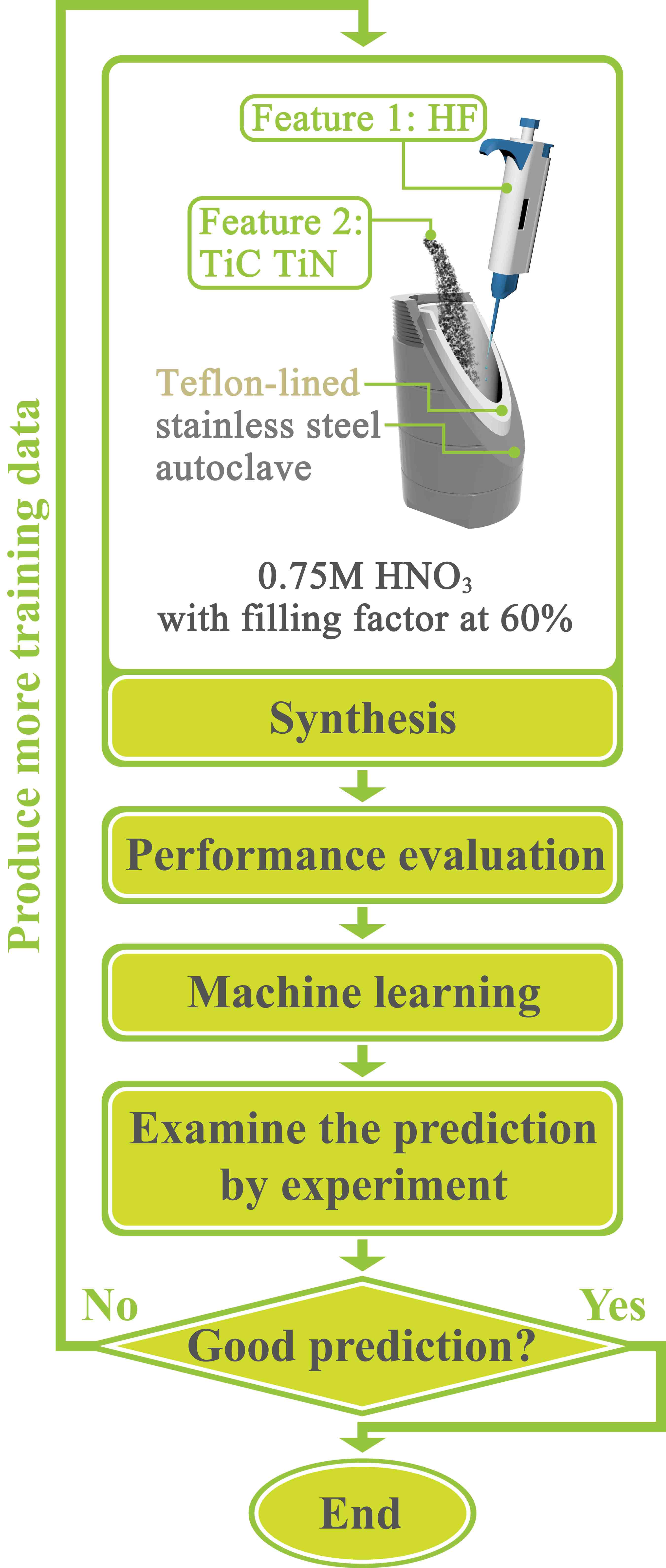
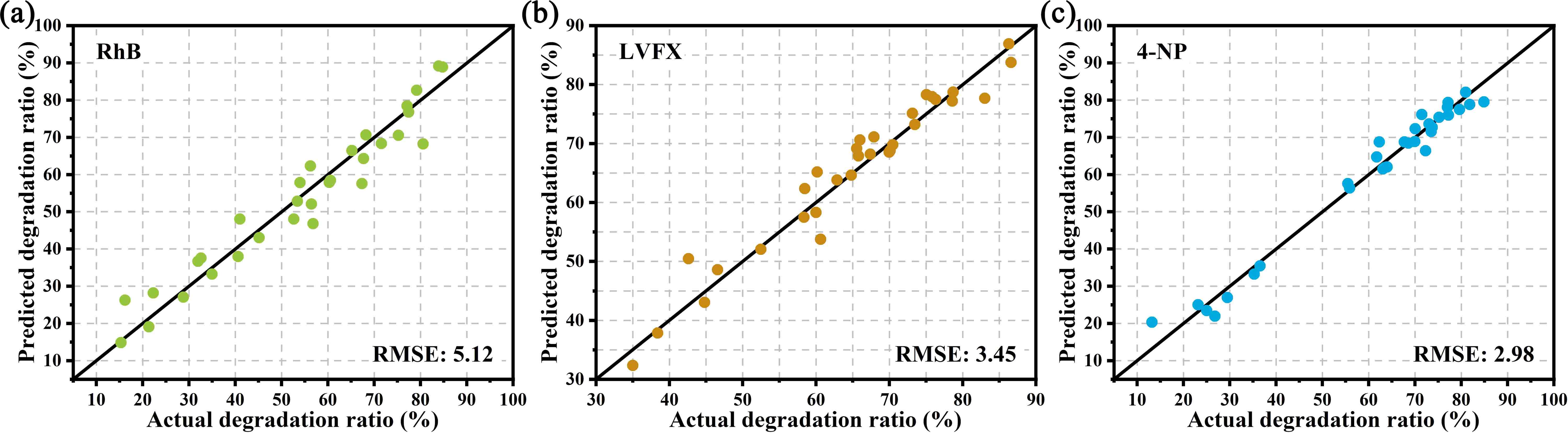
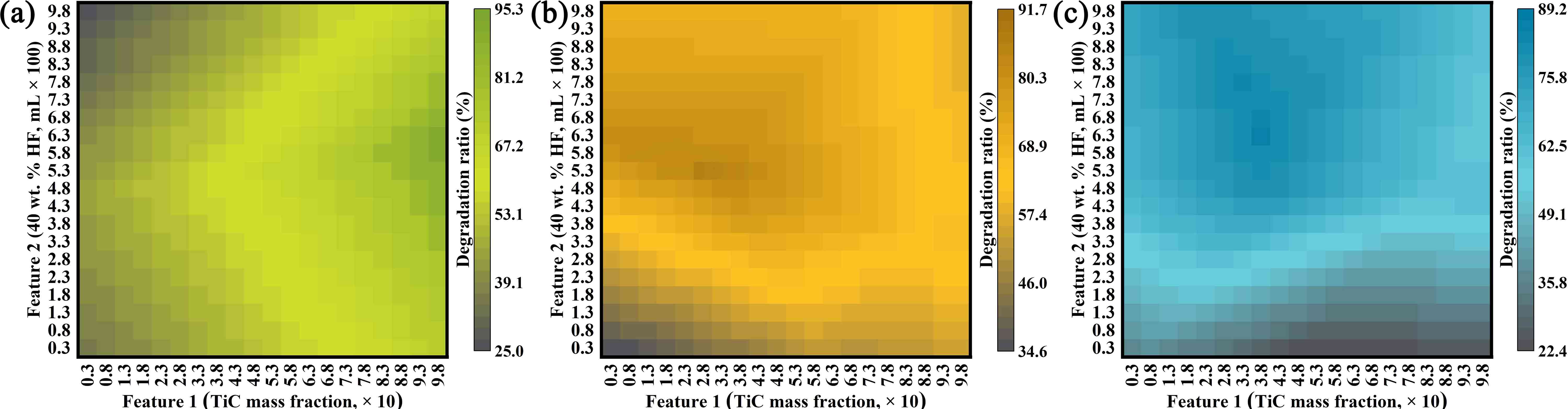
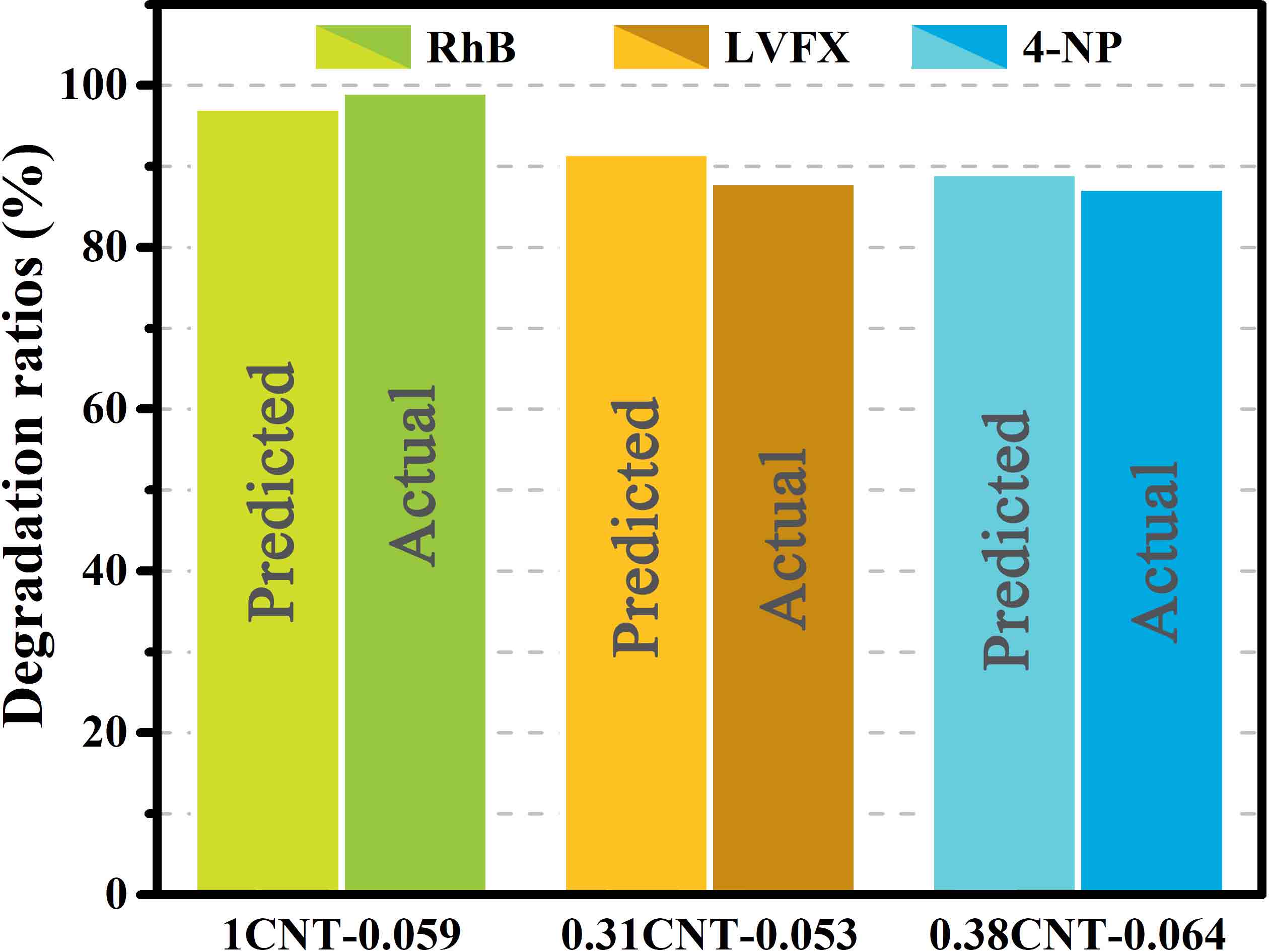
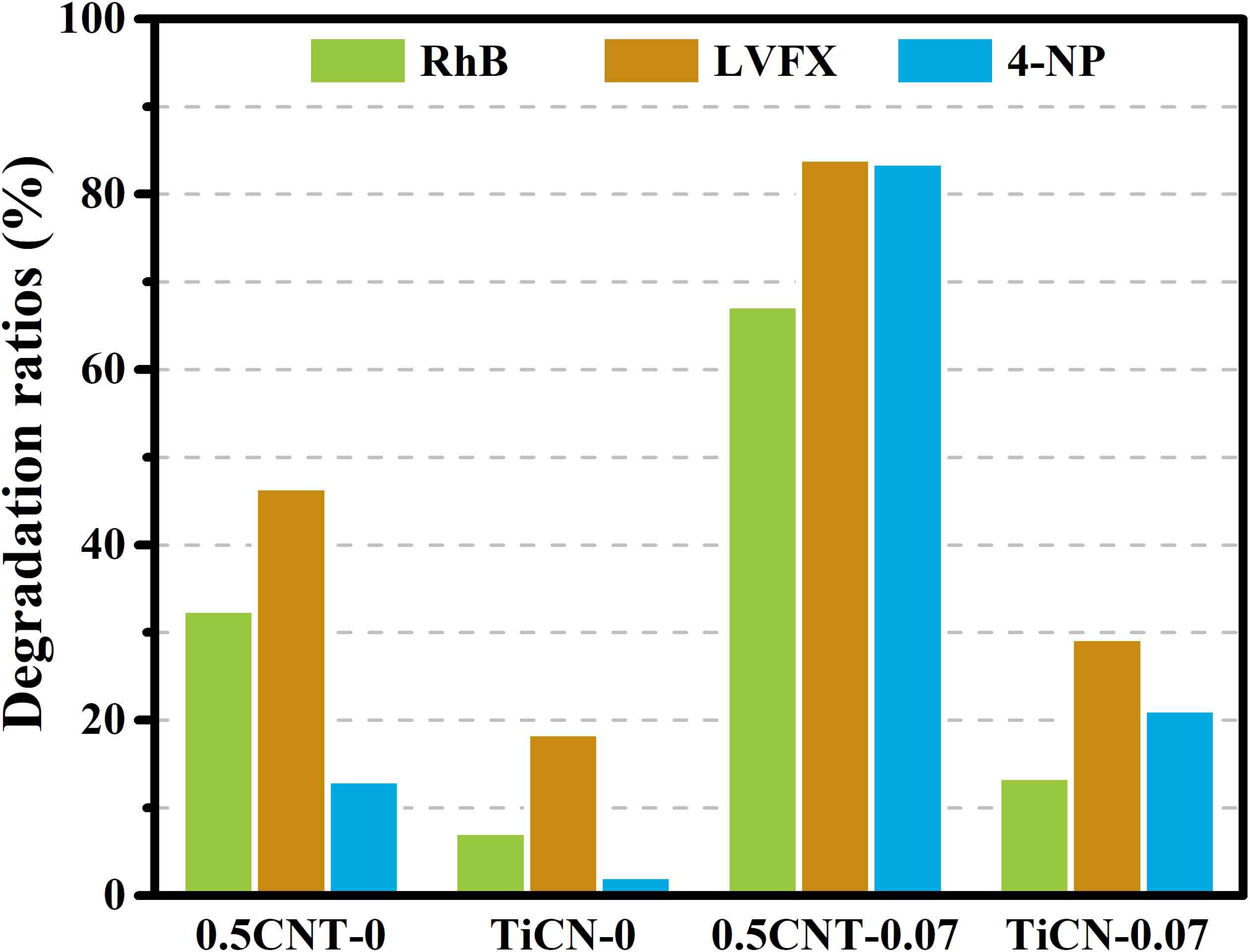
A paradigm for material synthesis is demonstrated under the guidance of machine learning as well as the designed wet-lab experiments. This work begins with a series of well-tailored experiments, including the synthesis of C/N-codoped TiO2 nanoparticles with exposed anatase {001} facets and its photocatalytic performance evaluations. In advance of applying machine learning, the underlying synergistic effects are revealed and expounded in detail purely based on wet-lab experiments. Then, the idea of active learning is adopted by implementing a multi-step workflow to iterate the experiments around preferred synthesis conditions, and unravel the optimum synthesis parameters with the assistance of machine learning. In this work, the prediction models are built on a solid physical and chemical understanding, rather than a ‘black box approach’. To this end, the designed experiments as well as the bootstrapping technique together guarantee a good prediction with less training. The compatibility of the artificial neural network and wet-lab experiment also endows the current strategy with several innate advantages. Moreover, controlled experiments with different starting materials were carried out. The results suggest that, in an effort to ensure more accurate predictions, further restrictions could be placed on data collection prior to the stage of introducing machine learning, and the design of wet-lab experiment plays a crucial role in facilitating machine learning. Lastly, the future prospect for machine learning-assisted material synthesis is briefly discussed based on the current work.